
LLMs are powerful tools, but interacting with them effectively can be surprisingly unintuitive.
Commonly, they’re dismissed as being nondeterministic, that for the same input they may produce a different output.
Prompt: Write a haiku about nature.
Option 1:
Morning light drips slow
Through pine needles, the earth breathes
A bird stitches dawn
Option 2:
Golden sun sinks low
Whispering through ancient pines?
Earth begins to sleep
Option 3:
Autumn leaves whisper
Secrets to the whispering wind
Silence in the fall
Prompt: Make a picture of a city built inside a coffee mug.
Coffee Mug City A

Coffee Mug City B

Coffee Mug City C

Indeed, same prompt, different results. However, I don’t think output variation is the real issue. Yes, LLMs use probabilistic sampling, but if we really wanted to, we could control that. We could pin a random seed and force the same prompt to produce the same output every time. That would trade away some creativity for consistency: mistakes would become perfectly repeatable, every “haiku about nature” would be identical, and benchmark scores would be static. Yet, I don’t think this would be better.
I believe nondeterminism is actually conceptually orthogonal to validity. If we forced an LLM to be perfectly deterministic, it wouldn’t magically make the outputs more accurate; it would just mean the model makes the exact same mistakes every time. Conversely, a system can be nondeterministic and still be perfectly valid. Take the .NET ThreadPool scheduler, for example, which deliberately makes no guarantees about thread execution order, yet no software engineer would argue the ThreadPool is inherently “invalid” just because its sequence fluctuates. The variation in ordering is just a property of the system, not a flaw in it. There are incorrect ways to use it, certainly, but the nondeterminism itself isn’t right or wrong, it’s simply something you design around.
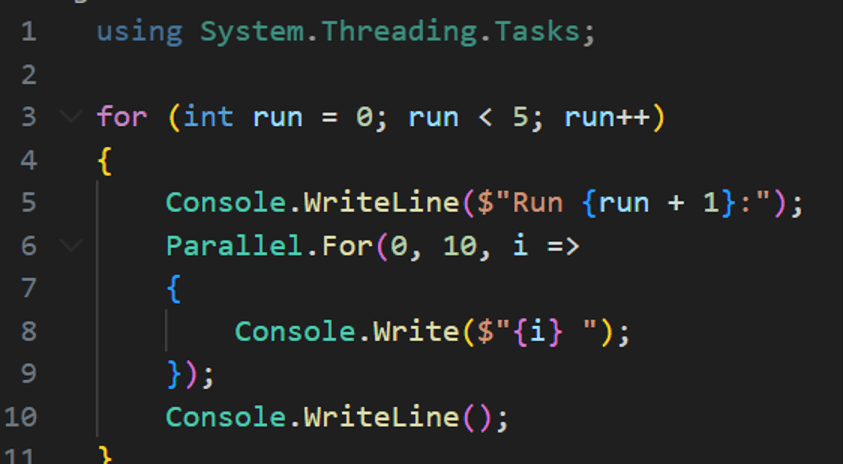
Output:
I believe the deeper problem isn’t that the output from LLMs varies between runs, it’s that the output is hard to anticipate in advance. For a given input, you often can’t predict the quality of the response before you run it. Variation is fine – we want the haiku to change. What’s unsettling is the volatility of validity: we don’t know whether the output will be true, hallucinated, or simply misunderstood. It can feel like a superposition of too-many plausible answers that collapses only when you hit “go.” That a priori uncertainty – not randomness by itself – is what makes these systems feel unreliable, unintuitive, and untrustworthy.
I’ll further break this uncertainty into two sources – mistake-driven uncertainty and language-driven uncertainty.
Mistake-driven: “The model tries to answer a well-defined question and may still fail”
Language-driven: “The question itself leaves degrees of freedom, and the model fills them.”
Let’s start with the first where AI is just wrong by looking at token probabilities.
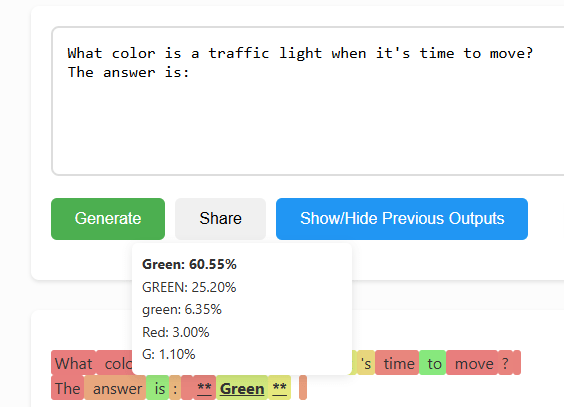
Source: https://tokenprobe.cs.columbia.edu/
What color is a traffic light when it’s time to move?
The answer is:
Some questions have an objectively correct answer. We expect Green, and while this model (Llama-3.1-8B, July 2024) did return the correct answer this time, analyzing its probability distribution reveals Red still had a 3% chance of being chosen. Here we can’t be certain about what the model will return because it has a significant chance of just making a mistake.
However, this is largely a hardware and architecture problem, and it is being solved rapidly. Fast forward to April 2025 with Qwen3-8B (same 8B parameter size, just better training) and the probability of Red plummeted to 0.4%. I suspect frontier models like GPT-5.2 (likely 1000B+ parameters) would return Red fewer than one in a million times (though I haven’t tried quite this many – that exercise is left to the reader).
As models improve – through scale, better training, and more capable architectures – their probability of making mistakes will continue to fall, especially in domains like coding and math where outputs are objectively verifiable (does this compile, is this calculation correct). Training techniques such as Reinforcement Learning with Verifiable Rewards push models toward correctness, not merely toward what word would commonly come next in their training corpus. As this error rate approaches zero, so does this source of uncertainty. We won’t need to run the prompt to see whether it returns Green; we’ll be able to safely assume that it will because validity will become the overwhelmingly most likely outcome. Over time, steady algorithmic progress, architectural advances, and billions in data center spending will gradually stamp out this category of uncertainty, irrespective of any changes in how we as humans interact with the model.
That first source of uncertainty comes from the model: even when a question is well-defined, the model may still make a mistake.
The second source – language-driven uncertainty – comes from us. In these scenarios, the model isn’t failing to answer the question correctly – the question or request itself leaves room for interpretation. It’s very easy to lossily translate an idea into words, and when intent is underspecified, the model is forced to invent the missing details. While that freedom is sometimes desirable, abdication of control should be done intentionally.
“Make a picture of a rocket”. You may have a clear picture in your head of what a rocket should look like, but the prompt only captured a fraction of that fidelity. Which direction is the rocket going? Is it currently launching, or is it already in space? Is it supposed to look like a photo, or a drawing? What time period? What color is it? Depending on the luck of random sampling, AI might choose to fill in these details significantly differently each time. In turn, you can’t be very certain about what that rocket is going to look like. As you input more exact language, though, and provide more structural specificity, the rocket will be more predictable.
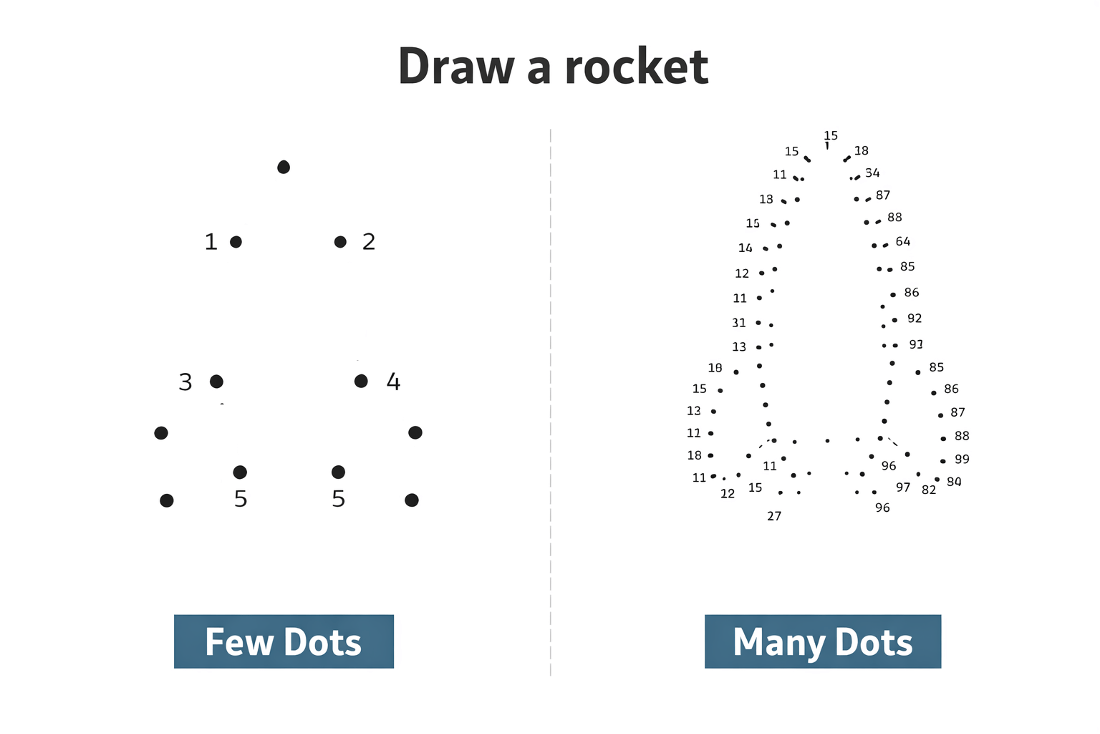
Let’s compare the predictability.
Prompt: Make a picture of a rocket.
Vague Rocket A

Vague Rocket B

Vague Rocket C

Low prompt specificity means the model gets to determine significant details, leading to a very large possible output space.
Prompt: A high-resolution, photorealistic image of a single rocket ascending at a precise 45-degree angle, nose pointing up and to the right. The rocket is fully visible in frame and occupies approximately 65% of the image width. Its body is made of brushed stainless steel with fine horizontal panel seams and visible rivets, exhibiting realistic specular highlights and subtle sky reflections. Three identical matte-red fins are mounted symmetrically near the base, slightly weathered and angled backward.
A single circular porthole window sits just above the vertical midpoint of the rocket, encircled by a thick metal rim with faint reflections of the sky and flame light. The nose cone is sharply conical, unpainted metal, marginally darker than the main body.
A bright, active engine plume is clearly visible, extending downward and slightly left from the engine bell due to the rocket’s diagonal trajectory. The exhaust consists of intense white-hot core flames transitioning to yellow, orange, and faint blue at the edges, with turbulent motion and realistic heat distortion. Dense, expanding exhaust smoke trails behind the rocket, partially obscuring the lower portion of the frame. The engine bell shows realistic heat discoloration and soot near the rim.
The rocket is photographed outdoors against a clear, pale blue daytime sky with no clouds, stars, people, text, logos, or additional objects. Sunlight comes from the upper left, while the flame plume casts a warm orange glow onto the lower fuselage. Depth of field is realistic with the entire rocket in sharp focus. Captured in a documentary-style photograph using a full-frame DSLR, 85mm lens, f/8, ISO 100, natural color grading, high dynamic range, cinematic realism.
Specific Rocket A

Specific Rocket B

Specific Rocket C

High specificity gives the model less wiggle-room, therefore making the outputs more controllable and predictable. There’s still some variation, but only in the more minor details I didn’t control, meaning the output is overall very close to what I intended. Of course, this exhaustive prompt took significantly more effort to write than just “make a picture of a rocket”, but still significantly less effort than it would have taken me to actually draw that picture of a rocket by hand (not that I even could draw it in such detail). It’s tempting to treat these models as a slot machine and hope the 0 effort prompt will happen to return the ideal solution on the first spin, but with how much effort it takes to correct bad (read: not what I wanted) output, I’ve found it’s almost always worth the extra time to write a better prompt from the start. Expecting a 400 line code change to be perfect based on a 4 line prompt is wishful thinking, but a 40 line prompt has a much higher chance of doing what you expect, and that’s still 10x fewer lines to type than coding directly.
This required specificity of language is inherently on us, not the model. It’s how we guide the system toward the output we actually need, rather than leaving critical decisions to chance.
When we apply this to software, code becomes the “pixel-perfect” rendering of our logic. Specificity of intent is always going to be important, but what we need to specify is shifting. Even today, prompts sometimes require annoying levels of guard-railing – “use this framework”, “check the imports”, “make sure unit tests pass” – just to restrict the LLM’s freedom to make mistakes. But as modern models like Claude Opus 4.6 demonstrate, that mistake-driven uncertainty is starting to evaporate, and we can delegate more of the implementation details to the model. We are approaching a point where most of our guidance can simply be a translation of business requirements, though naturally we’ll still have to be more specific than “make me an app, no bugs please”.
Just as it was significantly faster for me to describe the rocket in-depth than to hand-draw every rivet and reflection myself – and AI was a far better artist than I could ever hope to be – I believe it’s becoming faster to describe the requirements and logic of a system than to type out the boilerplate, error handling, and syntax manually. The model can “render” code faster, and soon perhaps more accurately, than a human can.
It’s not hard for me to imagine a not-so-far-off future where the true “source code” for most new applications is a set of Markdown files written in a mix of natural language and some code snippets. The actual implementation – be it C#, Rust, or Python – becomes effectively a compiled artifact, generated entirely by AI. When a change is needed, we won’t edit the C# code directly, we’ll update the Markdown spec and “recompile”. The uncertainty of “will the model correctly implement what was specified?” disappears. The only uncertainty left is: “Did I explain myself clearly?”.

Designing AI systems you can rely on
If you are exploring how to use large language models in real software, IntelliTect helps you turn clear intent into reliable, production-ready systems.